近日,数据库领域顶级会议VLDB 2023于2023年8月29日到9月1日在加拿大温哥华举行。在VLDB 2023上,jbo竞博体育官方网站共有7篇高水平论文入选。VLDB 会议全称 International Conference on Very Large Data Bases,是数据库领域历史悠久的三大顶级会议 (SIGMOD、VLDB、ICDE) 之一,每届会议集中展示了当前数据库研究的前沿方向、工业界的最新技术和各国的研发水平,吸引了全球顶级研究机构投稿。
jbo竞博体育官方网站本次被VLDB录用了7篇论文,研究成果涵盖了多个领域,包括大模型训练优化、自动化超参数调优、数据库性能优化、图数据挖掘等。
以下是论文简要内容介绍:
1. Angel-PTM: 一个部署在腾讯的经济高效可扩展的大规模预训练系统
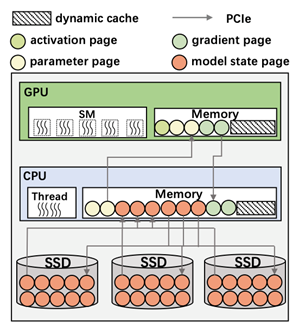
近年来,大规模预训练模型取得了前所未有的成就。腾讯公司的多款产品和服务,如微信、QQ和腾讯广告,已经广泛应用这些先进的预训练模型以提升用户体验和服务质量。文章Angel-PTM: A Scalable and Economical Large-scale Pre-training System in Tencent提出了Angel-PTM,一个专为大模型预训练而精心构建的工业级深度学习系统,可以利用GPU服务器中的多层存储高效地训练超大规模的模型。Angel-PTM 的关键设计在于其基于Page抽象的细粒度内存管理和一个统一视角的训练调度器,该调度器高效地协调了计算、CPU与GPU之间的数据传输以及GPU间的通信。此外,Angel-PTM通过使用SSD存储来支持超大规模模型的训练,并提出了无锁更新机制以缓解SSD I/O带宽瓶颈的问题。实验结果表明,相比现有系统, Angel-PTM在相同GPU资源下支持更大的模型训练(提升114.8%),且训练吞吐提升了88.9%。此外,我们还对AngelPTM在千卡A100 GPUs训练GPT3-175B和T5-MoE-1.2T模型的性能进行了测试,从而进一步验证了其出色的的可扩展性。
该论文第一作者为jbo竞博体育官方网站2019级博士聂小楠(导师崔斌教授),通讯作者为崔斌教授和2018级博士符芳诚,合作作者包括jbo竞博体育官方网站的苗旭鹏,腾讯公司的刘毅、薛金宝、焦点和陶阳宇。
2. SDPipe:一种半去中心化的异构感知流水并行训练框架
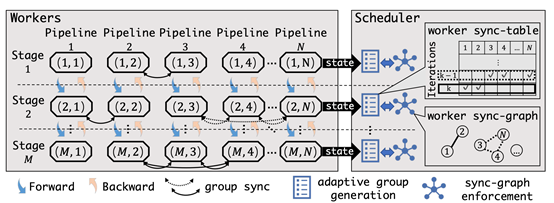
随着模型规模和数据体量的增长,流水并行作为一种常见的模型并行方法被广泛应用于各种分布式训练场景。然而,工业界的大多数大模型训练案例都是基于理想的同构集群。实际上,真实的GPU集群环境往往会伴随着动态的异构特性,造成大量的模型同步开销。现有方案中,无论是中心化的参数服务器,还是去中心化的集合通信原语,都面临着一定的性能瓶颈。文章SDPipe: A Semi-Decentralized Framework for Heterogeneity-aware Pipeline-parallel Training提出了一种半去中心化的异构感知流水并行训练框架。该工作将需要密集通信的模型同步操作以去中心化的方式完成,实现高效同步,并且以中心化的方调度节点通信组,灵活动态调整。SDPipe通过细粒度的跨流水线局部同步操作,替代了传统去中心化方案中的全局规约操作,并且通过同步图的全局约束,能够在保证模型收敛的同时提高分布式训练的通信效率。实验结果表明,SDPipe在真实异构集群环境下,可以显著超越现有方法的性能,并且具备较好的自适应能力和可扩展性。
该论文第一作者为jbo竞博体育官方网站2017级博士苗旭鹏(导师崔斌教授,现CMU博士后),通讯作者为崔斌教授,合作作者包括石屹宁、杨智副研究员、Zhihao Jia(Carnegie Mellon University)。
3. Galvatron:面向大规模Transformer模型的自动并行训练框架
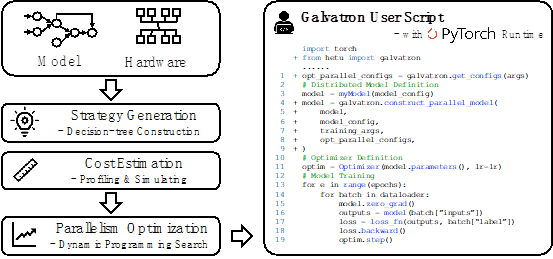
基于Transformer的大规模预训练模型已经成为了当前基础模型的核心架构,这类稠密大模型拥有着动辄数十亿、百亿甚至万亿规模的参数量,面临高昂的计算、存储、以及通信开销,也为AI基础设施带来了巨大的挑战。现有的并行训练工具(如Megatron、DeepSpeed等)提供了一些基础并行策略的支持,但仅靠这些工具进行训练往往会造成严重的资源利用效率低下的问题,常常需要依赖系统专家经验进行反复调试甚至二次开发,以满足性能的需求。文章Galvatron: Efficient Transformer Training over Multiple GPUs Using Automatic Parallelism提出了一套面向大规模Transformer模型的自动并行训练框架。相比于现有工作,该工作主要有三方面优势:1)可以支持更多的并行维度,并且具备面对差异化的模型结构和不同集群硬件条件下的自适应调优能力;2)面对庞大的搜索空间,设计了一套基于决策树剪枝和动态规划的智能优化算法,实现高效的分布式执行计划优化;3)结合理论建模与实验测量的优势,实现精确的内存、计算、通信开销估计,保证自动并行优化结果的准确性。Galvatron兼容PyTorch生态,用户使用友好,只需添加数行代码,就可以轻松完成大模型自动并行训练的整个流程,在多个常见Transformer模型场景下,分布式训练性能远超DeepSpeed、Magatron等现有系统。
该论文第一作者为jbo竞博体育官方网站2017级博士苗旭鹏(导师崔斌教授,现CMU博士后),通讯作者为崔斌教授,合作作者包括王驭捷、姜友和、石淳安、聂小楠、张海林。
4. Online-Tune: 通用高效的Spark在线参数调优框架
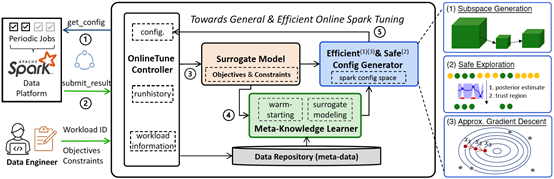
分布式数据分析系统Spark广泛应用于企业处理大规模数据,而参数调优对Spark中的任务执行性能有重要影响。传统的自动参数调优方法存在功能有限、高开销、搜索低效等问题。文章Towards General and Efficient Online Tuning for Spark提出了一个新的通用且高效的Spark参数调优框架Online-Tune。Online-Tune引入通用调优目标,并以贝叶斯优化为基础,支持多目标带约束复杂问题求解;在周期性任务的实际执行过程中执行在线参数调优,避免额外开销,并提出了一个安全采集函数,以确保在线调优的性能稳定性;提出自适应子空间生成、近似梯度下降、迁移学习三种方法,进一步加速调优过程。实验结果表明,Online-Tune在Benchmark和业界实际任务上的优化性能均超过现有方法,具有更快的收敛速度和更好的安全性保证。
该论文第一作者为jbo竞博体育官方网站2017级博士黎洋(导师崔斌教授,现腾讯高级研究员),作者包括姜淮钧、沈彧、崔斌教授(通讯作者)等。
5. CommunityAF:一种基于自回归流的社区搜索方法
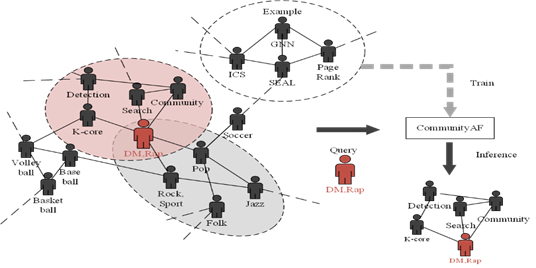
社区搜索旨在以查询请求的方式在复杂网络中获取用户感兴趣的稠密诱导子图(社区),搜索出来的社区可以用于朋友/商品推荐、异常检测等。 传统的方法基于用户预定义的规则搜索目标社区,难以结合图的语义特征并且对用户带来了较大负担。文章CommunityAF:An Example-based Community Search Method via Autoregressive Flow尝试将生成模型引入端到端的示例社区搜索任务。CommunityAF 利用增量 GNN 组件在大型底层图中学习节点嵌入以满足可扩展性,利用基于自回归流的生成组件进行快速并行训练,并利用学习节点嵌入的评分组件实现灵活终止。我们在训练期间使用平方排名损失来确保稳定性,并引入一种灵活的方式来根据波束搜索期间观察到的分数变化来结束社区生成过程。实验结果表明,CommunityAF 优于现有方法,并且可以学习各种社区模式。
该论文第一作者为jbo竞博体育官方网站2021级博士陈嘉尊(导师高军教授),作者包括夏逸宽、高军教授(通讯作者)
6. LOGER:面向高效稳定查询执行计划生成的学习型优化器
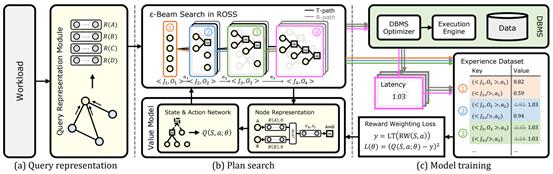
查询优化器的功能是对输入的查询产生对应的查询计划,是数据库管理系统中直接决定执行性能的重要模块。基于深度强化学习的查询优化器是研究热点,但是也面临着高效查询计划少、搜索困难、查询执行时间波动大等挑战,这些挑战使得这些方法难以稳定地产生高效的查询计划。针对以上挑战,文章LOGER: A Learned Optimizer towards Generating Efficient and Robust Query Execution Plans提出了一种新型的基于深度强化学习的查询优化器LOGER。该工作结合传统查询优化方法对查询计划的搜索空间进行重构,降低寻找高效查询计划的难度;提出一种新的强化学习探索方法,高效地在搜索空间中进行搜索;提出一种基于算子无关的执行时间的训练策略,通过降低执行时间波动有效提升训练稳定性。实验结果表明,LOGER在多个数据集上超过现有方法,并具有较高稳定性和边界性能。
该论文第一作者为jbo竞博体育官方网站2022级博士陈天异(导师高军教授),作者包括高军教授(通讯作者)、陈河堆(中兴通讯)、屠要峰(中兴通讯,通讯作者)
7. MiCS: 面向公有云超大模型训练的近线形扩展通信系统
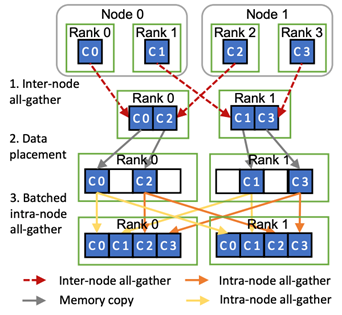
超大模型训练具有很大的网络开销,而公有云的网络环境复杂,导致使用现有框架训练超大模型时难以高效扩展。文章 MiCS: Near-linear Scaling for Training Gigantic Model on Public Cloud提出了一个面向公有云训练超大模型的近线形扩展通信优化系统MiCS。通过减少通信集合中的参与者数量,MiCS可以利用异构网络带宽,减少慢速链路上的网络流量,减少通信延迟以保持高网络带宽利用率,并摊销昂贵的全局梯度同步代价。实验结果表明,MiSC在公有云上的系统吞吐超过现有方法,达到接近线形的扩展效率。
该论文第一作者为约翰霍普金斯大学博士张桢(导师金鑫副教授),通讯作者为金鑫副教授和AWS的Shuai Zheng,合作作者包括AWS的Yida Wang、Justin Chiu、George Karypis、Trishul Chilimbi、Mu Li。


